Behind the scenes: Quiet before the storm... 😇


If you're following our "diary" here on this blog, you'll have noticed that we tend to get a little quiet right before something big happens ... 😈
Yep yep - we've been plotting and cooking things up in the background, and some exciting times are ahead. But first things first - let me tell you about some of the behind the scenes happenings of the recent months...
What we've been up to:
- Three datasets complete!
- Revalidation
- New data pipelines
- Improving training movie answers
- Machine learning
Coming next: (spoiler alert!)
- [New data](#data) - [Chatbox](#chatbox) - [Catchathon 2018](#catchathon)Datasets
So far in Stall Catchers (since our start in October 2016) we analyzed three major datasets from the Schaffer-Nishimura Lab at Cornell. (We are now completing our third.)
Validation
Our first dataset could be thought of as ground truth - we already had expert answers, so we used it to run a validation study and prove that crowd answers are just as accurate as experts'. We were overjoyed when the crowd (YOU!) not only met, but exceeded the stringent research requirements set by the lab!
 |
Results of our initial validation study. By testing catchers' joint answers against the ground truth provided by the lab, we demonstrated that stalls data can be analyzed reliably within Stall Catchers.
A lot has changed since our validation study was completed, however, like us switching to the dynamic stopping rule, which meant that our "magic number" went down from 20 to an average of 7 answers required to answer each movie with high confidence. (A major milestone!) |
Plaques
Next, we analyzed the "amyloid plaques" dataset, hoping to answer the question of whether plaques co-occur with stalls in Alzheimer's brain. As expected, our preliminary results drawn from Stall Catchers answers, showed they are not. We passed the baton to the Schaffer-Nishimura Lab, and hope to share more with you about what's happening with these data soon.
HFD
Our third dataset was concerned with the role of a high fat diet in the formation of stalls. We have been analyzing this dataset for almost a year, receiving it in several smaller data "batches". We're completing it now, but even early on our preliminary results showed that a high fat diet does indeed increase the incidence of stalls!!
We announced these initial findings at the British Science Festival in September 2017. We will share back a full report, once we get more feedback from the lab.

Revalidation
Ever got in trouble for unexpectedly out-performing classmates in school? (I have 😒) Well, that's how I like to think of the recent re-validation study we had to complete in Stall Catchers! 😇
Our validation study, conducted after the game launched in 2016, demonstrated that we are able to generate reliable "flowing" or "stalled" answers for vessel movies with the help with the crowd.
With this basis in confidence, we began applying Stall Catchers to analyze "real" datasets from the lab, including the high fat diet dataset (the one currently in stall catchers). Since a small part of that dataset had vessels that were already scored by lab experts, we showed the crowd answers for that subset to the lab. It came as a big surprise when they noticed there were big differences between the crowd answers and the expert answers. 😱 Our validation study had suggested otherwise!
Our first idea was that the data from the high fat diet study was visually much noisier than the previous datasets, so the validation results would not generalize to such noisy data. But then when we compared the expert's answers to each other we discovered that they experts themselves disagreed more with each other about vessels than the crowd disagreed with each expert separately! We also discovered that the crowd agreed most with vessels for which the experts were in agreement.
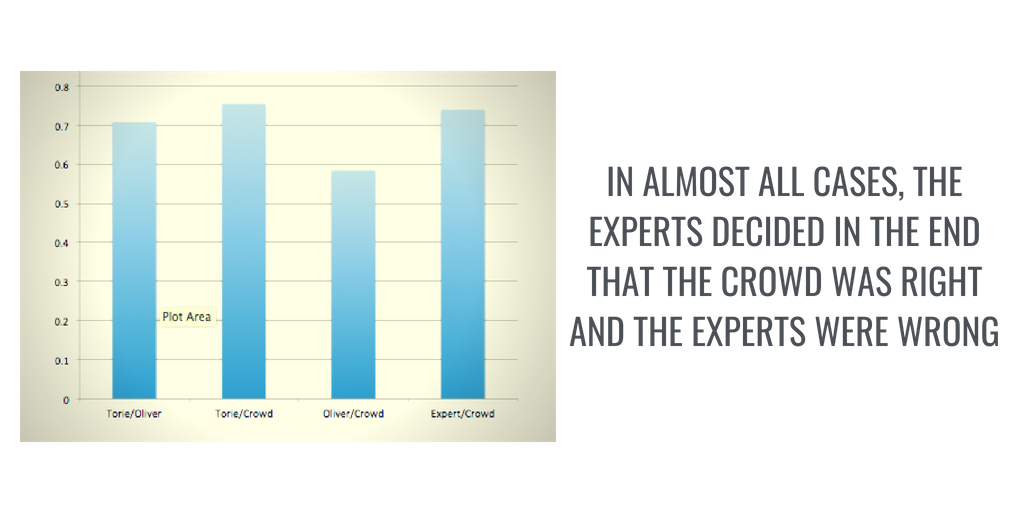
But the most surprising finding of all is that when the lab examined the individual vessels for which the crowd disagreed with the experts, in almost all cases, the experts decided in the end that the crowd was right and the experts were wrong.
Even though this reconfirmed that high data quality of answers emerging from SC, this process and the need for the lab to be able to do some level of verification for their own peace of mind, suggested an entirely new approach to providing answers to the lab, which meant we also had to run a whole new study to validate that new approach (revalidation!)

This was a major setback for us, in regards to getting fresh data into Stall Catchers, but we have now completed revalidation and have a solid, improved way of providing crowd-generated answers to the lab.
In the new approach, instead of providing crowd-generated answers that are categorical (either "flowing" or "stalled" and nothing in between), each vessel gets a "crowd confidence" rating between 0 and 1, where 0 is flowing and 1 is stalled. So if catchers decide a vessel is 0.3 that means it might be flowing. And then we provide the lab with an ordered list of all vessels that have a crowd confidence that is greater than zero.
In general, the stall rate, even in mice with Alzheimer's disease is very low overall - perhaps 5%. So for the research, it is critical to not miss counting any stalls.
So the new idea is that the list of vessels for which the crowd says there might be a stall (confidence > 0) will be a small percentage of all vessels that the lab could easily verify. So our new validation study had to check two things: 1) that the proportion of vessels that has nonzero crowd confidence is small enough for the lab to double-check (<10% of the full dataset), and 2) that the remaining vessels, with a crowd confidence of zero, contained NO stalled vessels, to ensure they aren't missed.
And to maximize the generality of these results, we combined three datasets for the validation study where we already new the answers - our calibration dataset (the ones you get points for right away), our original validation dataset, and the subset of the HFD dataset for which we had expert answers (and ultimately corrected our expert answers). We used a resampling technique to essentially conduct 200 mini-validation studies, and kept a randomly select portion of the data set aside for testing.
This rigorous approach took some extra time to execute, but was ultimately successful in validating the new approach and demonstrating its feasibility for the Cornell lab moving forward.
Once the Cornell Lab saw the validation study results they agreed to send new data into stall catchers, and this time, they gave us data that tests a drug target related to preventing stalls, called a NOX2 inhibitor. If the results emerging from the SC analysis for this drug target look promising, it could lead to preclinical trials.

Pipelines
As we told you in the recent post on this blog, we've also been putting "user interface" features on hold to develop some very important "backstage" features. Our new data pipelines will ensure we can efficiently receive, process, analyze and track Alzheimer's research data from Cornell.
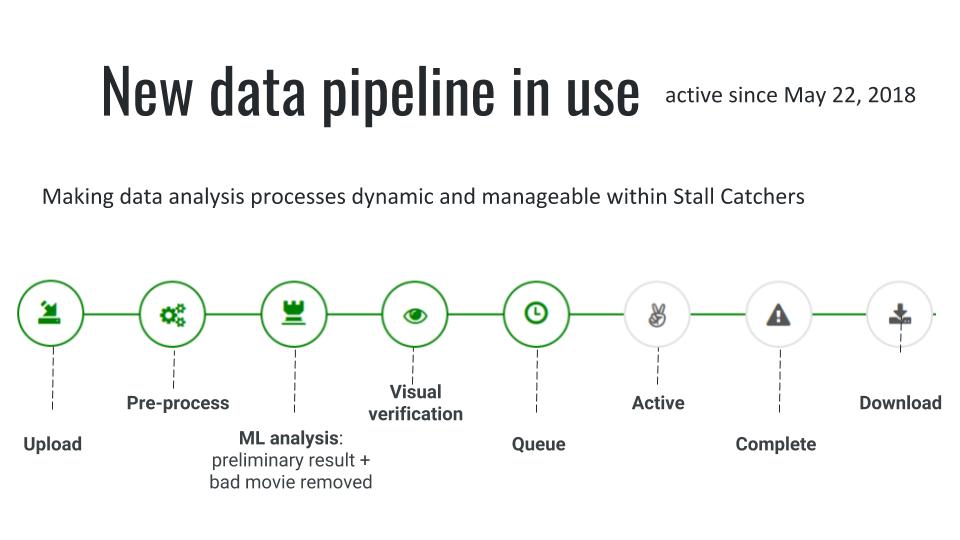
Read all about it here.
Training
We've been mediating between some of our superusers and the Cornell lab to improve expert answers on some of the trickier training movies!!
We heard you on the forum, and the vessel comments, and, with the kind (and priceless!!) help of gcalkins and caprarom, are in the process of updating the expert answers that were generated by them, and approved by the lab!
The lab said they were very impressed by the training movie answers that gcalkins and caprarom generated!!!
Overall, I'm very impressed with the comments - please tell them that. I think superusers are as good as anyone in the lab!
Nozomi Nishimura, Schaffer-Nishimura Lab
ML
Our developer and machine learning researcher Ieva has been working on developing new methods for cleaning Stall Catchers datasets before we give them to you to analyze, as well as automatic pre-classification of the easier vessels.
Cleaning

The "cleaning" involves removing movies with "bad outlines" (bad tracing), e.g. if no vessel appears within the outline, a section of a large vessel is mistakenly outline (like a vein or an artery which we do not analyze), vessels are over-exposed, i.e. the light emitted from the sample makes it impossible to see it, and so on.
The new machine learning methods also help us remove vessels that are near the edges of the movie, making them difficult to analyze reliable, e.g. due to a part of a vessel being cut off.
As an example, of 105537 movies of the most recent high fat diet dataset, 22.11% movies were removed as vessels appeared near the edge, and ~15% were removed with the bad tracing model.
That makes it a lot easier on YOU - catchers, as with these methods in place, you won't have to look through too many "bad" vessels, which are imposible to annotate, and end up being flagged anyway.
Autoannotation
In Stall Catchers our goal is to annotate/classify vessels as stalled and flowing with very high accuracy (95%), and for that we have to rely on the human eye (YOUR eyes! 👀).
However, some vessels are very obviously flowing and twe're getting better at classifying them automatically. One of the things we've been working on, is creating a machine learning model that can correctly identify and pre-select the clearly flowing vessels.
In the future, as the machine learning algorithms get better, we can combine the best skills of us humans and computers in more ways in Stall Catchers, which will help us do more, and speed up the research even more!
Next...
---> SPOILER ALERT! <---
## DataWe have a new dataset in our possession!! It is not in Stall Catchers yet, because this is the first time we are using the new pipelines AND pre-processing the data ourselves, so it's taking a little time to set up.
On the bright side, having this system and being able to prep the data ourselves is going to ensure we can get new datasets a lot more easily to Stall Catchers from now on!
We will make an official announcement once the new data is ready to be analyzed, but for now - another spoiler alert! It's dealing with a molecule that may help uncover the molecular pathways underlying stall formation in Alzheimer's.
Put simply in another one of Lisa's videos! :
Chatbox
As already mentioned, we had to put some user-facing features on hold for a while, to make sure that the machinery of Stall Catchers itself is working well, we are getting new data, and our volunteers' efforts are not wasted.
But you are not going to be left unrewarded for your patience! 😄 A feature that we've promised a while ago - chatbox - has been developed and is now being tested on our development servers 🎉
This will be a minimal version, but we will add to it as we go. It will support group chat, have pinned messages, and this and that! The desktop version to be released first, followed shortly by mobile.
Catchathon
This year, the Second International Stall Catchers Catchathon is happening on World Alzheimer's Day, September 21st!
It will actually be a 48 hour period, from the first minute it's September 21st somewhere on the planet, to the last. We hope to gather teams across the world to participate in the Golden Hour as well, 16:00 UTC, September 22, standing together as a planet for one hour to fight Alzheimer's.
More information soon, but you can already sign up via this form:
That's that for now!! Stay tuned - storm is coming!..;) 🌪
